[Python] 纯文本查看 复制代码
import re
import json
import requests
# 页数
page = 4
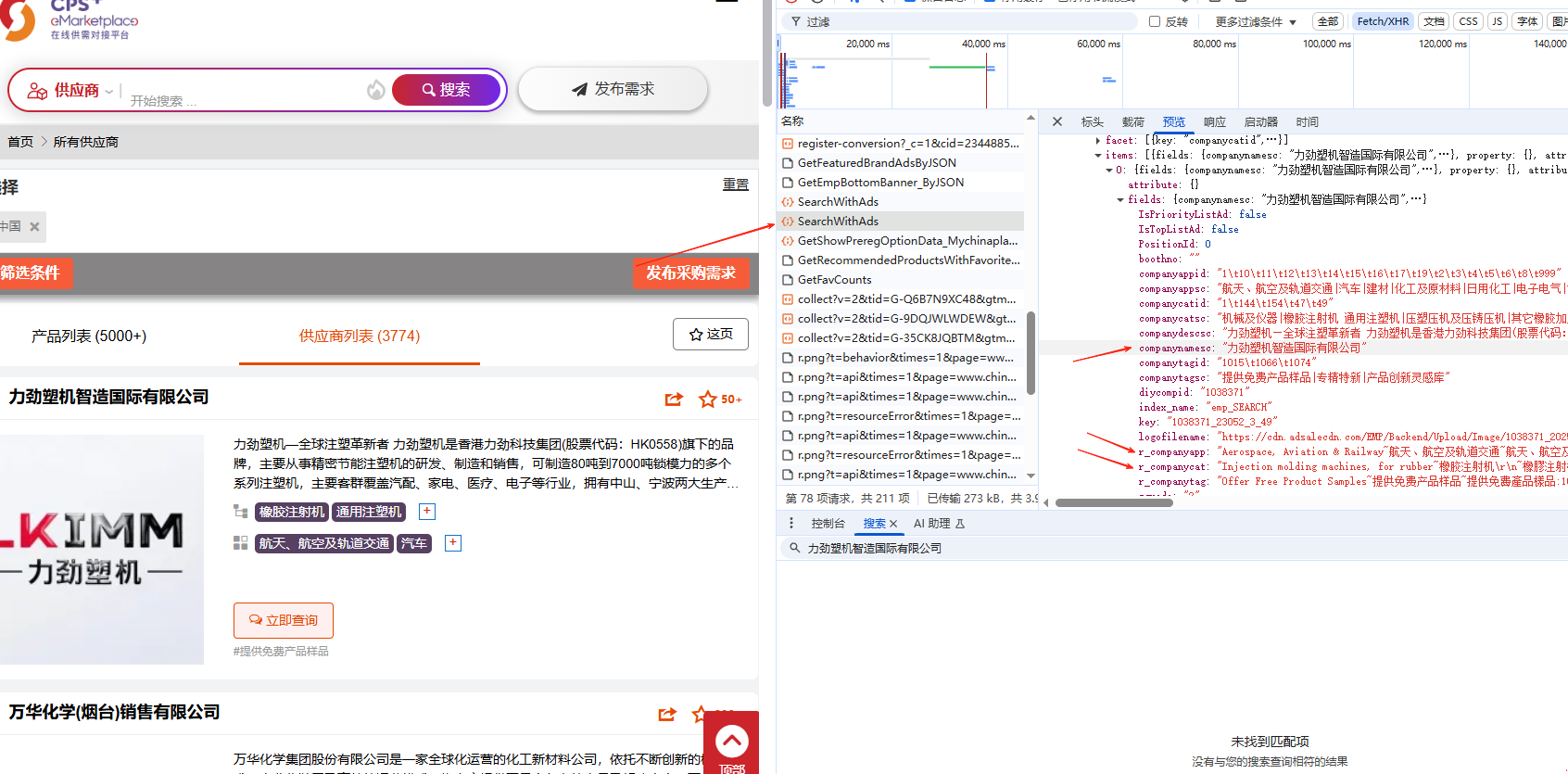
url = "https://api.chinaplasonline.com/WebCoreAPI_Search/OpenSearch/SearchWithAds"
payload = json.dumps({
"log": {
"LangId": "",
"SearchBy": "Exh",
"Keyword": "",
"IP": "127.0.0.1",
"Page": page,
"VistorGuid": "",
"AdsaleGuid": "",
"SourceName": "eMarketpalce",
"SelectedCriterion": {
"Prods": [
""
],
"Apps": [
""
],
"Tags": [
""
],
"Regions": [
"44"
],
"TechAreas": [
""
],
"ThemeZone": [
""
],
"Halls": [
""
]
},
"IsCountPage": False
},
"model": {
"Start": str((page-1)*15),
"Size": "15",
"Fetch_fields": "key;diycompid;companynamesc;sponsorid;sgrade;boothno;companytagid;companycatid;companycatsc;companyappid;companyappsc;liveurlsc;liveTitlesc;videofilename;logofilename;companydescsc;companytagsc;r_companytag;r_producttag;r_companycat;r_companyapp",
"Query": "(comp_info_a:'' OR comp_info_b:'' OR comp_catapptagkey:'') AND seqid:(-1,)&&distinct=dist_key:diycompid,dist_count:1,dist_times:1,reserved:false,update_total_hit:true&&kvpairs=duniqfield:diycompid&&aggregate=group_key:companycatid,agg_fun:count(),max_group:4&&sort=+comp_orderingsc&&filter=(companycountryeformid=\"44\")",
"second_rank_name": "comp_adv",
"first_rank_name": "sys_first_default",
"Disable": "qp:spell_check",
"raw_query": ""
},
"searchParams": {
"langId": 936,
"catIds": "",
"appIds": "",
"exZone": 0,
"type": "Exh",
"keyword": "",
"tagIds": "",
"themezone": "",
"halls": "",
"regions": "44",
"IsCPSListOnly": False
}
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
responseJsonObject = json.loads(response.text)
for item in responseJsonObject['data']['body']['result']['items']:
print(f"标题:{item['fields']['companynamesc']}")
print(f"简介:{item['fields']['companydescsc']}")
labels = re.findall('~(.*?)~', item['fields']['r_companycat'].replace('\r\n','').replace('\n',''))
print(f"标签:{'、'.join(labels)}\n")

 粤公网安备 44522102000125 增值电信业务经营许可证 粤B2-20192173
粤公网安备 44522102000125 增值电信业务经营许可证 粤B2-20192173


 发表于 2025-4-16 22:25:02
发表于 2025-4-16 22:25:02

 主题置顶卡
主题置顶卡 沉默卡
沉默卡 变色卡
变色卡
 扫一扫,关注易界动态
扫一扫,关注易界动态