|
一、认识Locust 1、定义 Locust是一款易于使用的分布式负载测试工具,完全基于事件,即一个locust节点也可以在一个进程中支持数千并发用户,不使用回调,通过gevent使用轻量级过程(即在自己的进程内运行)。 2、特点 ①、不需要编写笨重的UI或者臃肿的XML代码,基于协程而不是回调,脚本编写简单易读; ②、有一个基于we简洁的HTML+JS的UI用户界面,可以实时显示相关的测试结果; ③、支持分布式测试,用户界面基于网络,因此具有跨平台且易于扩展的特点; ④、所有繁琐的I / O和协同程序都被委托给gevent,替代其他工具的局限性; 3、locust与jmeter的区别 工具 | 区别 | jmeter | 需要在UI界面上通过选择组件来“编写”脚本,模拟的负载是线程绑定的,意味着模拟的每个用户,都需要一个单独的线程。单台负载机可模拟的负载数有限 | locust | 通过编写简单易读的代码完成测试脚本,基于事件,同样配置下,单台负载机可模拟的负载数远超jmeter |
PS:但locust的局限性在于,目前其本身对测试过程的监控和测试结果展示,不如jmeter全面和详细,需要进行二次开发才能满足需求越来越复杂的性能测试需要。 二、安装Locust 1、支持的python版本:2.7、3.4、3.5、3.6; 2、Windows系统安装locust ①、直接通过 pip install locustio 命令安装; ②、通过为pyzmq、gevent和greenlet安装预先构建的二进制包,然后在这里找到非官方的预制包,下载.whl文件后,使用 pip install name-of-file.whl 命令安装; 安装成功后可以输入 pip show locust 命令查看是否安装成功,以及通过 locust -help 命令查看帮助信息。 PS:运行大规模测试时,建议在Linux机器上执行此操作,因为gevent在Windows下的性能很差。 三、一个简单的示例 locust的脚本里,模拟负载的请求和python的requests库使用方法基本一样,示例如下: [url=] [/url] [/url]
1 # coding=utf-8 2 import requests 3 from locust import HttpLocust,TaskSet,task 4 from requests.packages.urllib3.exceptions import InsecureRequestWarning 5 # 禁用安全请求警告 6 requests.packages.urllib3.disable_warnings(InsecureRequestWarning) 7 8 class MyBlogs(TaskSet): 9 # 访问我的博客首页10 @task(1)11 def get_blog(self):12 # 定义请求头13 header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36"}14 15 req = self.client.get("/imyalost", headers=header, verify=False)16 if req.status_code == 200:17 print("success")18 else:19 print("fails")20 21 class websitUser(HttpLocust):22 task_set = MyBlogs23 min_wait = 3000 # 单位为毫秒24 max_wait = 6000 # 单位为毫秒25 26 if __name__ == "__main__":27 import os28 os.system("locust -f locusttest.py --host=https://www.cnblogs.com")[url=][/url]
脚本说明: 新建一个类MyBlogs(TaskSet),继承TaskSet,该类下面写需要请求的接口以及相关信息; self.client调用get和post方法,和requests一样; @task装饰该方法表示为用户行为,括号里面参数表示该行为的执行权重:数值越大,执行频率越高,不设置默认是1; WebsiteUser()类用于设置生成负载的基本属性: 属性 | 说明 | task_set | 指向定义了用户行为的类 | min_wait | 模拟负载的任务之间执行时的最小等待时间,单位为毫秒 | max_wait | 模拟负载的任务之间执行时的最大等待时间,单位为毫秒 |
PS:默认情况下,时间是在min_wait和max_wait之间随机选择,但是可以通过将wait_function设置为任意函数来使用任何用户定义的时间分布。 四、启动Locust 1、如果启动的locust文件名为locustfile.py并位于当前工作目录中,可以在编译器中直接运行该文件,或者通过cmd,执行如下命令: locust --host=https://www.cnblogs.com 2、如果Locust文件位于子目录下且名称不是locustfile.py,可以使用-f命令启动上面的示例locust文件: locust -f testscript/locusttest.py --host=https://www.cnblogs.com
3、如果要运行分布在多个进程中的Locust,通过指定-master以下内容来启动主进程 : locust -f testscript/locusttest.py --master --host=https://www.cnblogs.com
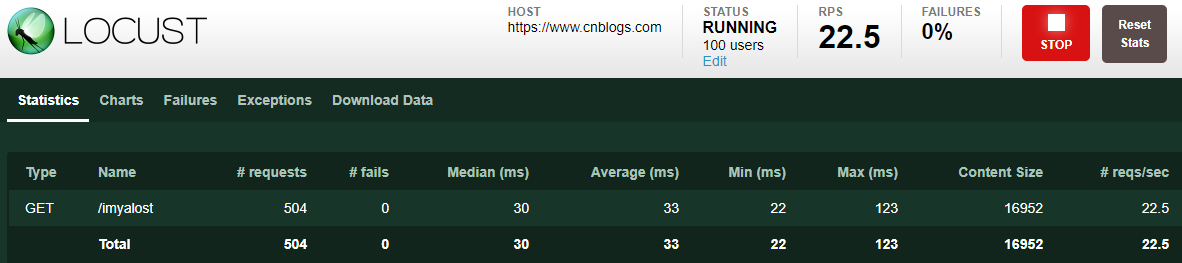
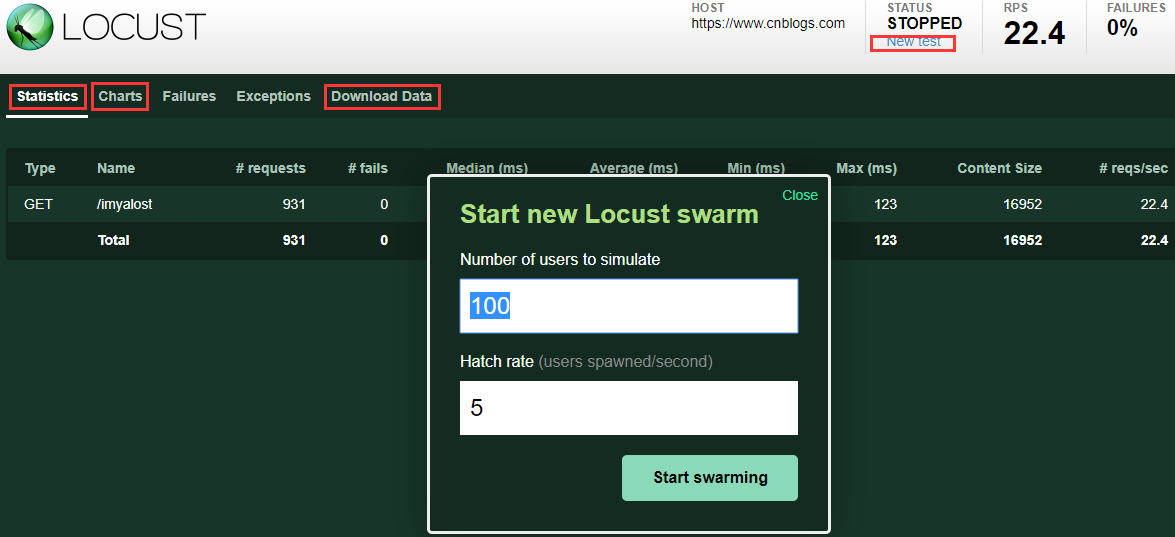
4、如果要启动任意数量的从属进程,可以通过-salve命令来启动locust文件: locust -f testscript/locusttest.py --salve --host=https://www.cnblogs.com 5、如果要运行分布式Locust,必须在启动从机时指定主机(运行分布在单台机器上的Locust时不需要这样做,因为主机默认为127.0.0.1): locust -f testscript/locusttest.py --slave --master-host=192.168.0.100 --host=https://cnblogs.com 6、启动locust文件成功后,编译器控制台会显示如下信息: [2018-10-09 01:01:44,727] IMYalost/INFO/locust.main: Starting web monitor at *:8089 [2018-10-09 01:01:44,729] IMYalost/INFO/locust.main: Starting Locust 0.8 PS:8089是该服务启动的端口号,如果是本地启动,可以直接在浏览器输入http://localhost:8089打开UI界面,如果是其他机器搭建locust服务,则输入该机器的IP+端口即可; 五、locust的UI界面 1、启动界面 Number of users to simulate:设置模拟的用户总数 Hatch rate (users spawned/second):每秒启动的虚拟用户数 Start swarming:执行locust脚本 2、测试结果界面 PS:点击STOP可以停止locust脚本运行: Type:请求类型,即接口的请求方法; Name:请求路径; requests:当前已完成的请求数量; fails:当前失败的数量; Median:响应时间的中间值,即50%的响应时间在这个数值范围内,单位为毫秒; Average:平均响应时间,单位为毫秒; Min:最小响应时间,单位为毫秒; Max:最大响应时间,单位为毫秒; Content Size:所有请求的数据量,单位为字节; reqs/sec:每秒钟处理请求的数量,即QPS; 3、各模块说明 New test:点击该按钮可对模拟的总虚拟用户数和每秒启动的虚拟用户数进行编辑; Statistics:类似于jmeter中Listen的聚合报告; Charts:测试结果变化趋势的曲线展示图,分别为每秒完成的请求数(RPS)、响应时间、不同时间的虚拟用户数; Failures:失败请求的展示界面; Exceptions:异常请求的展示界面; Download Data:测试数据下载模块, 提供三种类型的CSV格式的下载,分别是:Statistics、responsetime、exceptions; 以上即为locust的介绍和简单使用以及说明,更多详细的内容请参考官方文档。。。
| 
 粤公网安备 44522102000125 增值电信业务经营许可证 粤B2-20192173
粤公网安备 44522102000125 增值电信业务经营许可证 粤B2-20192173


 发表于 2020-2-6 15:23:11
发表于 2020-2-6 15:23:11


 主题置顶卡
主题置顶卡 沉默卡
沉默卡 变色卡
变色卡


 楼主
楼主 扫一扫,关注易界动态
扫一扫,关注易界动态